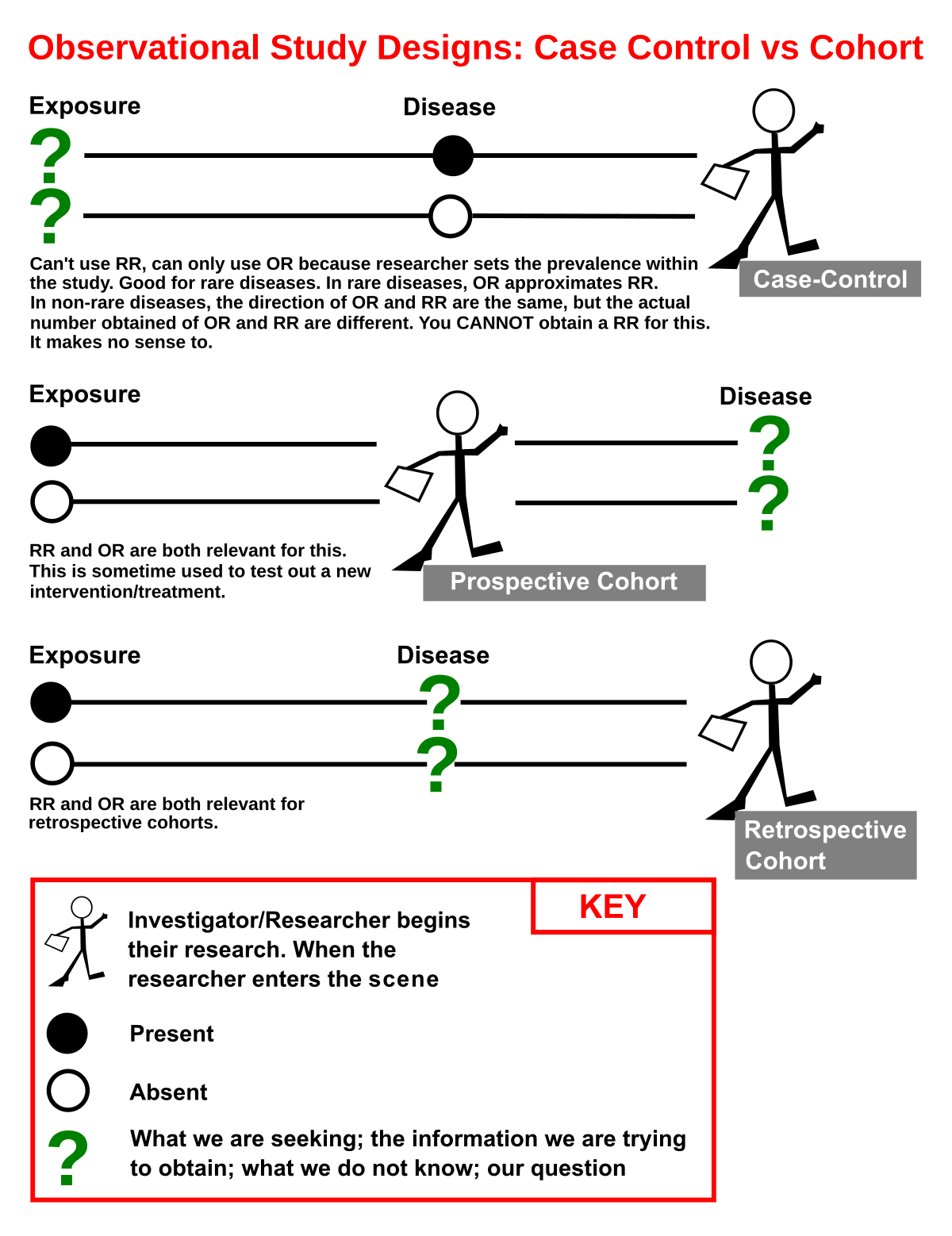
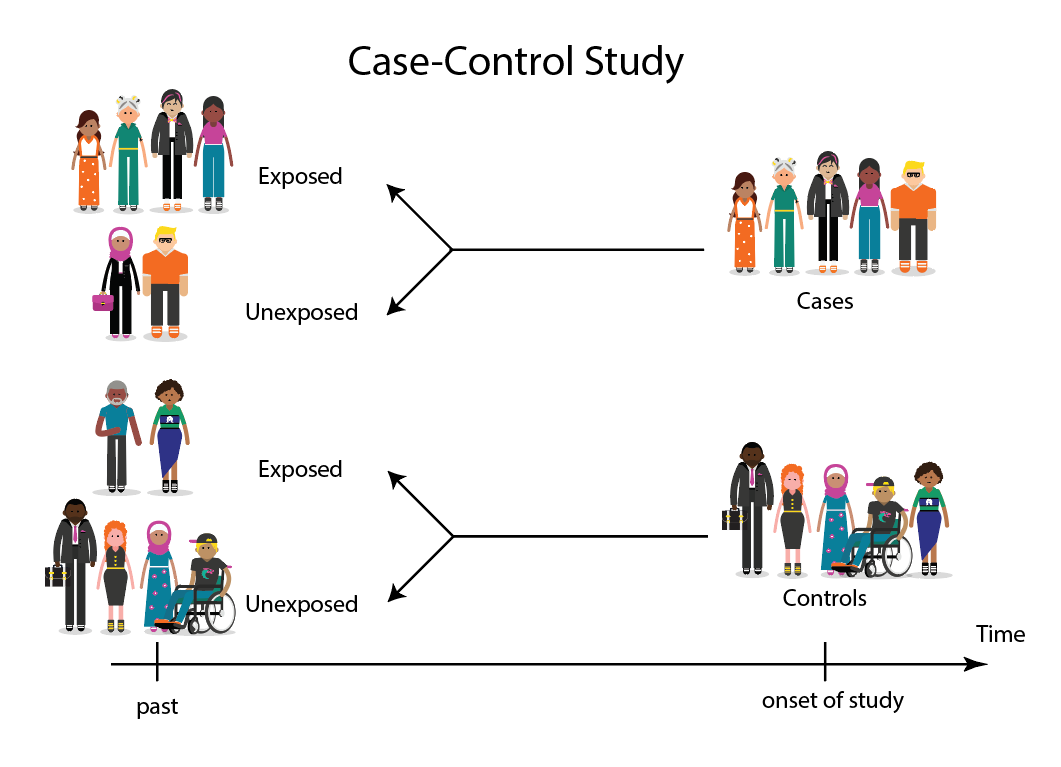
If you’re conducting a case-control study, you must choose a set of predictor variables for the cases and controls. These variables should be chosen with great care, as not all are equally important. The following are some tips on how to choose predictive variables for case control studies. Consider their reliability and measure heterogeneity. You should also keep in mind the matching criteria. Using one case per control would be unfair, but using a different number of controls would be a valid method.
Reliability of predictor variables
Reliability of predictor variables in a case control study is a crucial aspect of conducting a risk assessment. To be reliable, the study controls must be representative of the same population as the cases and be at risk of becoming a new case. In general, the study ratio is one case to four controls. However, there are some considerations to make when deciding on the study design. For instance, the more heterogeneity in the case population, the lower the chances of finding a specific risk factor to be associated with the disease. In contrast, a narrower disease category might be more appropriate if the study population is representative of the general population.
Reliability of predictor variables for a case control study may also be affected by overmatching, an issue that is common in the design of NCC studies. This problem can introduce bias into the estimation of the outcome of a case-control study, which can result in biased results. Breslow and colleagues reported on simulations that involved single binary exposures, single-factor match factors, and multiple scenarios.
Importance of more than one control per case
Case-control studies have two main drawbacks. First, they cannot confirm the presence of different levels of disease in the control group. Cases are defined as either having or not having a condition. This means that, even though the study population is large, there may not be enough controls to generate statistical power. Second, the population is not representative of the general population. Finally, the case-control study is not appropriate for identifying a single risk factor for a particular disease, which makes it less useful for a population-based study.
To avoid this problem, it is important to include more than one control for each case. While a study can be conducted on only a sample of the population, a random sample is not feasible in many situations. A large number of cases may not have sought medical care, or may have been mislabeled by different physicians. For these reasons, researchers often choose a sample of a population and select controls from that group.
Penalised regression
In a case control study, you may want to use a statistical method to help you select the most predictive variables. This is known as penalised regression. Penalised regression allows you to minimise the error of prediction. Typically, a single predictor is the most useful; however, you can also combine several factors to create one predictive variable. Nevertheless, if your case control study involves several different variables, you may want to consider a hybrid approach, which penalises other variables but not the treatment variable.
There are many disadvantages of using this method. It tends to screen out variables with weak effects. It also fails to select all variables in a collinear group. In high-dimensional data, the Lasso method may not be appropriate because it can only select n variables. This is where you can use the Elastic Net, a modification of Lasso. Elastic Net uses both L1 and L2 penalisations to encourage grouped selection.
Taking into account measurement heterogeneity
If you’re considering conducting a case control study, you should consider the measurement heterogeneity in your data. Measurement heterogeneity in the predictor variables can reduce the power of your CPR. Therefore, you should assess each outcome variable independently to avoid ‘incorporation bias’ or circular reasoning. Unfortunately, this is not always possible, especially if your outcome variable is a consensus diagnosis. Taking this factor into account can ensure that you’re minimizing potential problems with prediction accuracy.
Another consideration when analyzing case control data is selection bias. This bias can influence the results and inferences you make. For example, Mezei and Kheifets (2006) found that in a retrospective case control study, selection bias leads to an overestimation of the odds ratio by about two times. However, by using the methods described in this paper, you can adjust for selection bias in case control studies. This paper applies to a range of different types of studies and can be used for other purposes as well.